Next: 3D Reconstruction
Up: Correspondence Analysis
Previous: Phase Difference
Feature-based Correspondence Analysis
In contrast to intensity-based methods, feature-based methods first search striking parts inside the image and use the features found for the correspondence analysis. Some advantages of this method are
- faster computation
- because only features have to be compared. Using intensity-based methods for every pixel a depth value has to be computed, thus for every pixel a window has to be extracted and compared with a window which is centered at every pixel along the epipolar line. The costliest part of the feature-based correspondence analysis is normally the extraction of the features. The subsequent part of the comparison concerning needed computational power is mainly influenced by the amount of features found.
- lesser ambiguities
- due to the smaller amount of possible matches, lesser ambiguities during the comparison can occur.
- less sensitive
- comparisons between features are less sensitive to illumination changes than intensity based comparisons because intensity values are not used.
- high accuracy
- the disparity between features can be computed using subpixel accuracy.
In contrast to intensity-based methods, a feature-based approach yields a sparse disparity map, thus depth values are only known for corresponding features found and not for every pixel. Interpolation can be used to get a denser disparity map.
Typical features are
- Edge points
- Edges are abrupt significant changes in the signal level and can be computed using convolution masks.
- Line segments
- A line is a set of edge-points which are connected and form a straight line.
- Corners
- Corners are local image features characterised by locations where variations of intensity values in

 and
and  direction are high. In contrast edges are characterised by locations where variations of intensity values in a certain direction are high while variations in the orthogonal direction are low. Different corner detectors exist, most frequently used is the Harris [HS88] and the KLT(Kanade-Lucas-Tomasi) operator.
direction are high. In contrast edges are characterised by locations where variations of intensity values in a certain direction are high while variations in the orthogonal direction are low. Different corner detectors exist, most frequently used is the Harris [HS88] and the KLT(Kanade-Lucas-Tomasi) operator. - Regions
- The process of grouping pixels into regions of similarity is called segmentation. There are two main approaches used for segmentation, namely
- Region Splitting
- The basic idea of region splitting is to break the image into a set of regions which are coherent within themselves. In the beginning the region is the image itself. If the whole region fulfills some similarity constraint the segmentation is done. If this is not true, the region is splitted into equal parts, usually four. This is done until the regions satisfy the prevailing circumstances. The worst case is that every region just contains one pixel. After the splitting process, it is highly likely that some neighbouring regions have similar properties. Thus, a merging process is used after each split. The algorithm is finished if no further splitting is needed.
- Region Growing
- The main idea of the region growing algorithm is to take a pixel inside the image which is called the seed. If the neighbouring pixels fulfill a similarity constraints, the pixel is added to the region. If no pixels can be added any more, another pixel which is not yet in a region is chosen as the seed and the growing starts again. If every pixel is inside a region the process stops.
The similarity between two features can be defined as the weighted sum of the differences between their properties. For example the similarity of two lines ![]()
![]() and
and ![]() could be defined as
could be defined as
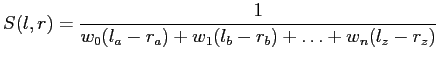 | (2.33) |
| (2.34) |
Next: 3D Reconstruction
Up: Correspondence Analysis